







Science/Research 詳細
最もスマートなAIモデルでさえ人の視覚処理にかなわない
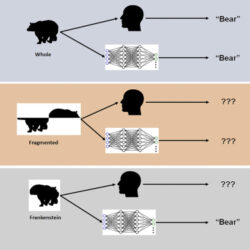
October, 6, 2022, Toronto--York UniversityのJames Elder教授によると、ディープ畳み込みニューラルネットワーク(DCNNs)は、人が見るように、形状認識を使ってモノを見ない。それは、実世界のAIアプリケーションでは危険になり得る。
iScienceに発表された「深層学習モデルは、人の形状認識の構成的性質を捉えることはできない」という論文は、Elder(York Research Chair in Human and Computer Vision)とシカゴのLoyola College、Nicholas Baker教授との共同研究。
その研究は新しい視覚刺激 “Frankensteins”を利用して、ヒトの脳とDCNNsが、全体的、後世的対象の特性をどのように処理するかを調べた。
「Frankensteinsは、分解され、間違った方法で元に戻された物体に過ぎない。結果として、それらは全て適切な局所的特徴を備えているが、場所が間違っている」(Elder)。
研究によって、人の視覚系は、Frankensteinsによって混乱させられるが、DCNNは違う、構成的物体の特徴に影響されないことが確認できた。
「われわの結果は、ディープAIモデルが、ある条件下では失敗する理由を説明している。さらに、脳における視覚処理を理解するために対象認識を超えたタスクの必要性を指摘している」。「これら、ディープモデルは、複雑な認識タスクを解決するとき、‘shortcuts’(近道)をする傾向がある。これらショートカットは、多くの場合、うまく行くかも知れないが、われわれが現在、産業や政府パートナーと取り組んでいる実世界のAIアプリケーションでは、危険となる場合がある」とElderは指摘している。
そのようなアプリケーションの1つは、交通ビデオ安全システムだ。「交通量が激しい状況における対象、車輌、自転車や歩行者は、互いに邪魔し合い、ドライバーの目には分離された断片の寄せ集めとして到達する。脳は、それらの断片を正しくグループ化し、物体の正しいカテゴリーと位置を確定する必要がある。断片を個別に知覚するだけの交通安全モニタリング用AIシステムは、このタスクに失敗し、交通弱者のリスクを誤解する」。
研究チームによると、そのネットワークを一段と脳のようにすることを目的とするトレーニングとアーキテクチャに対する変更は、構造的処理にならず、試行錯誤で人と物体判定を正確に予測できるネットワークはなかった。「われわれの推測では、人の構成的感度に合致させるためには、ネットワークは、カテゴリー認識を超えて、もっと広範なオブジェクトタスクを解決するように訓練しなければならない」とElderは話している。
(詳細は、https://www.yorku.ca)



![]()
関連雑誌: Laser Focus World, Laser Focus World China

Copyright © 2011-2021 e.x.press Co., Ltd. All rights reserved.
