








Science/Research 詳細
高効率なAI処理を行うプロセッサーアーキテクチャーを開発
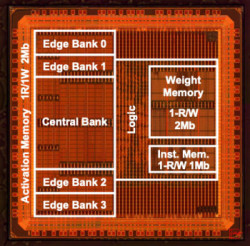
August, 30, 2021, 東京--東京工業大学 科学技術創成研究院の本村真人教授と安藤洸太特任助教は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が進める「高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発」で、エッジ機器で高効率な畳み込みニューラルネットワーク(CNN)推論処理を行うプロセッサーアーキテクチャーを開発し、大規模集積回路(LSI)を試作した。
今後、この技術の活用により、例えばスマートフォンにおける先進的な拡張現実(AR)アプリケーションやロボットにおける柔軟な動作制御など、電力供給量などの制約が厳しいエッジ機器でも高度なリアルタイムAI処理の単独での実行が期待できる。
従来の深く枝刈りされたCNNの推論処理では、メモリへのアクセスが不規則になるため計算効率が低下するという課題があった。
研究では既存のCNNモデルを変形して高精度で高効率な処理ができる形式に変換するアルゴリズムを開発した。さらに、このアルゴリズムを効率的に処理するための、入力データの平面シフトを扱う整形機構と直積型並列演算アレイを中核としたアーキテクチャーを提案。これにより試作LSIによる実測で、最大26.5 TOPS/Wという世界トップレベルの実効効率を達成した。
研究成果は、2021年8月22日から24日までオンラインで開催されたプロセッサーLSIの主要国際会議「Hot Chips 33」のポスターセッションで発表した。
今後の展開
エッジ機器で利用されるニューラルネット推論チップは、さらに高度な枝刈りや量子化による小型化が進むものと予想される。東工大とNEDOの研究チームは、この研究の試作チップで実証した技術をさらに発展させ、枝刈り後の精度向上のための学習技術や、RISC-Vプロセッサーなどとのシステムレベル統合技術の開発など、より高精度・高効率なニューラルネット推論チップの実現を目指し、スマートフォンやロボットなどのエッジ機器での高度なAIアプリケーションの実現を目指す。
(詳細は、https://www.titech.ac.jp)



![]()
関連雑誌: Laser Focus World, Laser Focus World China

Copyright © 2011-2021 e.x.press Co., Ltd. All rights reserved.
