








Science/Research 詳細
フォトニックチップがスパイクニューラルシステムのリアルタイム学習を促進
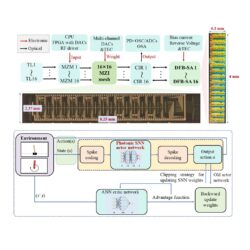
March, 18, 2026, Washington--中国西電大学(Xidian University)の研究チームは、フォトニックスパイキング神経システムとして知られるニューラルネットワークの主要な制約を克服するフォトニックコンピューティングチップを開発した。
純粋に光を使ったプロセスによる高速学習と意思決定を可能にすることで、電子機器ベースの計算は不要になる。この新しいチップは自律運転技術を向上させ、現実世界の相互作用を通じて学習するロボットシステムを実現にする可能性がある。
「フォトニックスパイキング神経系は、短い光パルス(スパイク)を使って神経シグナルを模倣するが、通常は光を使って計算の線形部分しか処理できない」と、中国西電大学の研究チームリーダー、Shuiying Xiangは話している。「以前は、学習や意思決定を可能にする非線形のステップは、信号を電子信号に戻す必要があった。これにより遅延が生じ、フォトニクスの速度やエネルギーの利点を損なっている。」
Optica Publishing GroupのOptica誌では、研究者たちは大規模なプログラム可能な非コヒレントフォトニックニューロモルフィック計算システムについて説明し、光学領域において線形計算と非線形計算の両方を実行できることを示した。この2チップシステムは、272のトレーニング可能なパラメータを持つ16chsのフォトニックニューロモルフィックチップを含み、複数の光信号ストリームを同時に処理し、学習を通じて多くの接続を調整する能力を備えている。
「このシステムを用いて強化学習を実証し、ニューラルネットワークを訓練・運用するハードウェアとソフトウェアの共同フレームワークによって支えられた。このシステムは試行錯誤を通じて迅速に学習でき、自動運転や具身型知能などのアプリケーションに使える高速かつ低遅延のソリューションとしての可能性を示した」(Xiang)。
オールオプティカル処理のための2チップシステム
「われわれのシステムは、大規模で低閾値の非線形フォトニックスパイキングニューロンアレイの欠如、完全にプログラム可能なフォトニックスパイキングニューラルネットワークチップの不在、そしてフォトニックスパイキング強化学習がハードウェアで実装可能かどうかという3つの重要な課題に取り組んでいる」(Xiang)。
研究チームは、スパイクニューラルネットワーク向けに設計された16×16 MZIメッシュチップと、低閾値非線形スパイキング活性化に最適化された飽和吸収体を備えた分散フィードバックレーザアレイ内蔵チップを設計・製造することでこれらの課題に取り組んだ。
また、ハードウェアとソフトウェアの協働トレーニングおよび推論フレームワークを開発し、モデルをまずソフトウェア全体で訓練し、その後チップ上で訓練し、最後にチップレベルの変動を考慮してソフトウェアで微調整する仕組みを行っている。
この新しい概念を検証するため、研究者たちはフォトニックニューロモルフィックチップにスパイキング強化学習アルゴリズムを展開する光電子ハイブリッドコンピューティングテストシステムを設計、構築した。その後、フォトニックニューロモルフィック計算システムが高速学習と制御を測定するためによく使われる2つのベンチマークタスクを実行できるかどうかをテストした。ある作業では、ポールを移動するカートの上にバランスを取る必要があり(CartPole)、もう一方では振り子を吊るした状態から直立した位置に振り回し、バランスを保つ(Pendulum)必要がある。
フォトニックスパイキングで強化学習
実験の結果、ハードウェアの決定精度はソフトウェア単独とほぼ同等で、CartPole課題ではわずか1.5%、振り子課題では2%の減少にとどまった。これは、チップがソフトウェアで訓練されたネットワークの挙動をリアルタイムで忠実に再現していることを示している。ハードウェアとソフトウェアの組み合わせを用いることで、CartPole課題で完璧なパフォーマンスを発揮し、より複雑な振り子課題でも良好な性能を発揮し、単純な学習課題からより難しい強化学習課題まで迅速かつ確実に対応できることを示した。
研究チームはまた、彼らのシステムが非常に高速で省エネルギー、かつコンパクトな計算を実現していることも示した。フォトニック線形計算においては、1Wあたり1.39テラの動作(TOPS/W)のエネルギー効率と0.13 TOPS/㎟の計算密度を達成した。一方、非線形計算では、1Wあたり987.65ギガ演算(GOPS/W)、533.33 GOPS/㎟を達成した。
これらの結果により、新チップはエネルギー効率の面でGPUクラス(~1 TOPS/W)の範囲に入り、計算密度の面ではGPUおよび応用特化集積回路(~0.1〜0.5 TOPS/mm²)の範囲に属している。さらに、オンチップの計算遅延はわずか320 psであり、オンチップ計算にかかる時間はわずか320兆分の1秒である。
今後、研究チームはより大規模な(128-ch)完全機能のフォトニックスパイキングニューラルネットワークチップを設計・製造し、ニューロモルフィック自律ナビゲーションのようなより複雑な強化学習課題を解決したいと考えている。また、この技術が、エッジコンピューティングのシナリオで実用的になるには、コンパクトなハイブリッド統合型大規模フォトニックニューロモルフィックチップの実証も必要になる。



![]()
関連雑誌: Laser Focus World, Laser Focus World China

Copyright © 2011-2021 e.x.press Co., Ltd. All rights reserved.
